作者:镜亦非台
链接:https://www.zhihu.com/question/31540524/answer/53097381
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
感谢
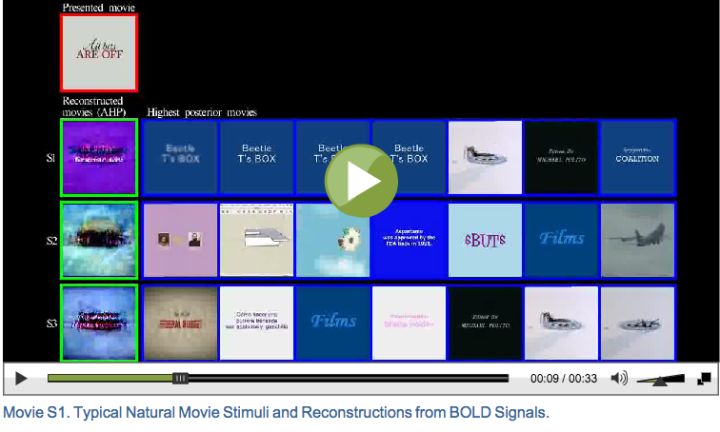
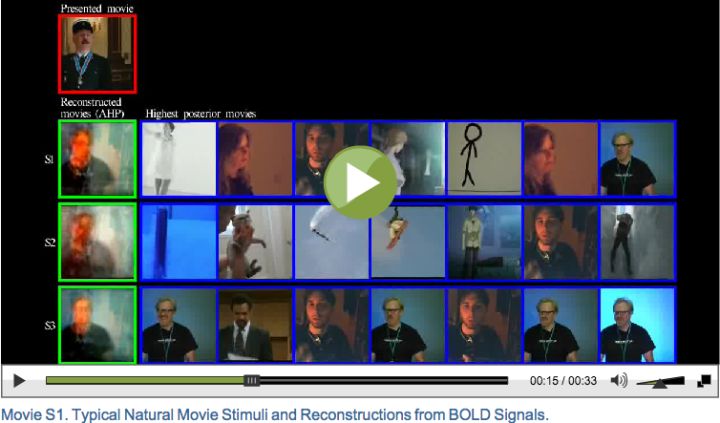
和 的邀请。首先楼主给出的截图来自UC Berkeley的Jack Gallant lab 2011年发到Current Biology的文章:Reconstructing Visual Experiences from Brain Activity Evoked by Natural Movies: Current Biology 网站上有他们的重建效果的视频,感兴趣的可以去看看(以防有些同学没有阅读权限,这里附几张视频截图)。
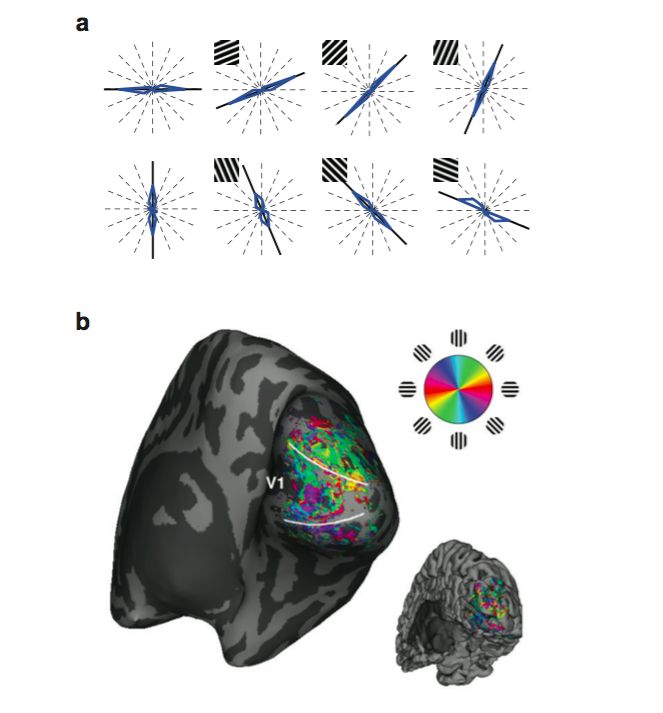
大家或许没有想到,其实关于brain decoding的研究已经有不少(科学家就是在“偷偷摸摸”做大家看不到的事情),这些研究主要用machine learning的方法,开创性的研究在2001年由Haxby和同事完成, 他们利用fMRI结合machine learning的算法,实现了预测被试在MRI scanner中看到的是人脸还是房子,还是猫,还是鞋子... 2005年的时候Kamitani和Tong, 利用fMRI解码出了被试看到的grating的方向,如下图(其实没有必要放这个图,不过好像有个研究说相较于行为数据,人们更愿意相信有大脑图的结果,所以无论如何也得放个脑图上来)
另外最近(2014)也有篇重建人脸(静态) 的文章也很有趣:Neural portraits of perception: Reconstructing face images from evoked brain activity 可见这个重建brain image/representation的技术是逐渐发展的,并不是忽如一夜春风来的。因为brain decoding是很复杂也很有趣的课题,答主时间和水平有限不能展开讲,所以接下来我就只针对性地回答一下楼主提到的这篇文章的原理。
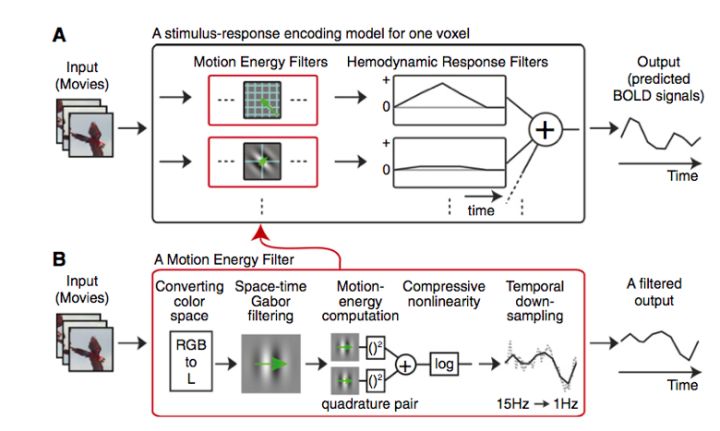
如果楼主阅读过原文的话,应该发现文章的大量篇幅其实是在自(炫)豪(耀)地讲他们之前提出的一种新型的encoding model (编码方法,有decoding自然也就有encoding)如何如何好,这种叫作motion-energy encoding model的方法(主要是用来model对运动物体的感知的)的特别之处呢在于克服了fMRI研究的一个局限:fMRI主要是以BOLD(blood oxygen level-dependent, 血氧依赖水平)信号来间接反映神经元信号的,fMRI分析的假设认为只要相应的神经元被激活了,BOLD信号就会开始增加,但是实际上它们并不同步,BOLD信号要比神经活动慢一些,比如说BOLD信号的peak点就比神经活动的peak点要慢6s左右。最常用的假设的BOLD信号模型如下图1,我们可以看到神经活动大概过了6s后,BOLD的曲线才慢慢到达顶点。但是BOLD信号变化这么滞后,怎么能快速反映瞬息万变的世间万象和心理变化呢?这个问题深深地深深地困扰着很多fMRI研究者。所以这篇文章的算法解决了这个问题,“顺便”重构了一下看电影片段时的fMRI信号来验证,然后我们就被震惊啦,纷纷拜倒在大牛手下!
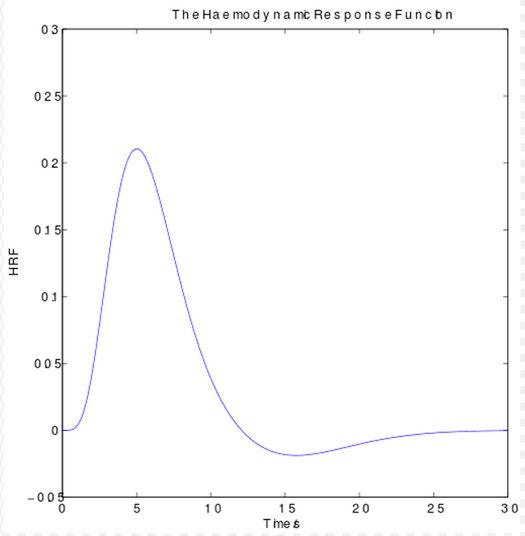
图1(来自维基百科).
其实基本的过程就如楼上
所说,我这里只是增加一些细节内容。作为machine learning的方法,首先他们需要training data,这里的training data是观看7200s的电影片段相对应的位于后侧和腹侧枕颞视觉皮层(posterior and ventral occipitotemporal visual cortex)的BOLD 信号,BOLD信号记录下的是观看电影时视觉皮层特定区域的整体活动,这样是不能用来建立fMRI活动和视觉图像的对应关系的,所以他们用了某种叫做nonlinear spatiotemporal motion-energy filter 的过滤器来提取图像的特征 (这里叫filters,但是我感觉应该是特征的意思), 比如位置,方向,空间,时间频率啊这些,如图2B 所示。然后再把这些特征与BOLD信号(也就是图2A中的Hemodynamic response)结合起来,每一个特征对应一种特定的BOLD曲线(运用了L1-regularized linear regression的方法),把这些曲线合在一起就是预测的BOLD 信号。这里是用training data得到的模型,然后他们又把这些模型用到540s电影(新的电影片段)的test data上面,拿预测的BOLD信号与实际的BOLD信号作比较从而判断模型的准确性(通过计算两者的相关性)。为了显示自己模型的优越性,作者拿了另外两个模型作比较,最后当然如我们所料,作者的模型“完胜” (差异显著啦!!)。
前面大费周折说了那么多,总结一下就是作者的encoding model是可以用来预测看natural movie时的BOLD信号的!
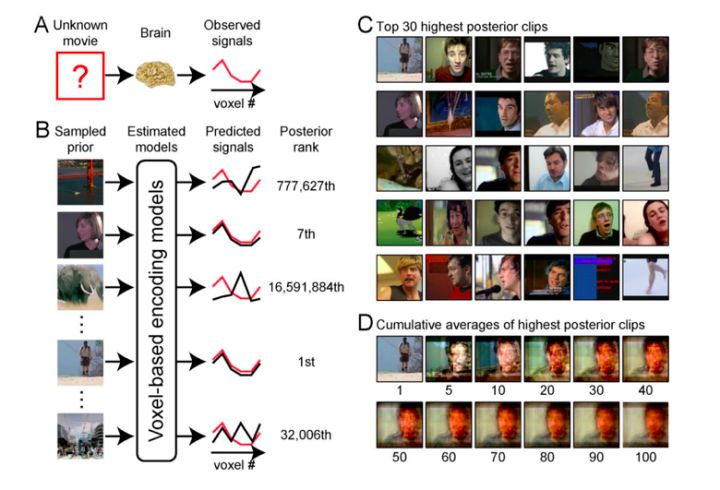
下面是大家比较感兴趣的重建(reconstruction)过程, 所谓重建就是利用BOLD信号来重构图像,传统的fmri研究是刺激→BOLD信号这样一个过程,重建就是反过来BOLD信号→刺激的过程,也就是传说中的“读心术”。重建的刺激是新的电影片段,BOLD信号来自视觉皮层。首先要说明一下这个重建并不是真的直接提取大脑信号来重建,而是先建立一个包罗众多电影片段的数据库(18 million second,5000小时),然后用上述的encoding model来建立新输入的视觉刺激与BOLD信号之间的关系(predicted signal),通过比较预测的信号与实际测量的信号(被试在MRI scanner里面躺了5000小时???)来对数据库中的收录的电影片段(1s)进行一个排名(图3B),图3C就是与站立人像的BOLD信号最接近的30副图。所谓的解码也就是在记录被试看影像时的BOLD信号的同时,比对数据库中已存的实际影像的BOLD信号,然后找出最接近的片段。图4看起来更清楚,红色方框里就是所谓重构的图像,按照接近程度进行排列,如果数据库中的图像和看到的图像比较接近,解码效果就比较好,反之,效果就比较差。楼主给的图的右侧看起来比较模糊,是因为那幅图是100张图平均的结果,并不是一幅图,也就是图4的AHP(averaged high posterior)。至此,重构过程也就完成了。2013年的时候,日本的学者发了一篇science用的是类似的方法来解梦,感兴趣的可以移步看一下:Neural Decoding of Visual Imagery During Sleep
如果大家觉得这样的黑科技出来,以后人类就没有隐私了,因为我心里想什么就会被知道了(心理学的学生窃喜终于可以回答“你知道我心里在想什么吗?”这个高深莫测的问题了)那就实在高估现在的技术水平了。首先MRI那么昂贵笨重的机器在那里,直接就限制了这项技术的商业化运用;其次整个编码解码过程都需要被试的高度配合(告诉大家一个诀窍,如果那天你被人强制读脑的话,你只要摇晃一下脑袋,数据就不能用了。不过,做实验的时候千万不要动!!要听主试的话!!),这也是为什么文中只用了三个被试,而且都是合作者(永远不要低估研究者发文章的决心!);再者,解码的算法还需要很大的改进,因为不是直接解码,所以从图4中可以看出解出来一些奇怪的画面。不过不管怎么说,这篇文章的想法真的很独特,虽然说这种想法本身就会导致重构图像的不精确,不过技术进步那么快,相信未来的发展会更加超出我们的想象的!

后记: 今年学期要结束的时候,Dr. Gallant来我们系做一个讲座介绍他的研究,不得不说Gallant lab做的研究真的特别impressive,有兴趣的朋友可以去他的实验室lab看一下(Gallant Lab homepage),重建视觉信息只是他研究的一部分,他们还有很多有意思而且很重要研究正在进行。Dr. Gallant在讲座的时候说他不是一个psychologist,因为那些高级的认知功能太复杂恐怕这辈子都搞不清楚,但是视觉区域的研究已经相对比较透彻了,所以他有生之年还有可能见到搞清楚的一天。这篇文章也正如他说的那样,主要在讨论技术层次的问题,涉及到fMRI技术,信号处理还有贝叶斯统计方面的内容,基本上和认知功能没有太大联系。虽然有些fMRI的经验,但是有太多不熟悉的概念,我个人阅读起来还是挺费劲的,有不少地方理解的也不清楚,如果表述有什么不对的地方还请轻拍和指正。谢谢!
References:
Haxby, J. V., Gobbini, M. I., Furey, M. L., Ishai, A., Schouten, J. L., & Pietrini, P. (2001). Distributed and overlapping representations of faces and objects in ventral temporal cortex. Science, 293(5539), 2425-2430.
Kamitani, Y., & Tong, F. (2005). Decoding the visual and subjective contents of the human brain. Nature neuroscience, 8(5), 679-685.
![]()
In collective intelligence I trust
收录于编辑推荐 ·
利用fMRI信号重建视觉场景,是一种对神经活动的解码,本质上是神经编码的一个逆问题。
顺便说一句,题主将问题做了变动,实际上原标题更确切。因为论文的工作是用fMRI信号重建受试者看过的视频。新标题中中“大脑中浮现的画面”也可以理解为在不看视频的情况下想象出来画面,如是与原文工作有所出入;另外,在这种条件下用fMRI信号反推“浮现”的画面,具有更大的挑战性。
基于大脑反应重建视觉刺激(图像或者视频)的研究并不新鲜,而且也不局限于用fMRI信号重建。Yang Dan 博士(现在UC Berkeley)在上个世纪90年代就用神经元的放电活动重建视觉场景(文献[1-3])。因为没有对神经解码类课题的一手研究经验,而且很长时间不看这方面的文献了,只能依据一点初浅理解对题主的问题做个概略性的回答。欢迎批评指正。
1. 视觉神经通路编码和fMRI信号的产生
虽然从技术角度并非必须(文献[4]),了解视觉神经编码和fMRI信号的产生原理,可以帮助理解为什么可以用fMRI信号重建视觉场景。视觉神经编码的基础知识在任何一本基础性的神经生物学都有介绍。
关于编码:(1)从眼球的后壁视网膜开始,到外侧膝状体 (LGN),到初级视觉皮层 (V1),到后面分化的视觉通路上(腹侧-ventral和背侧-dorsal pathway),视觉神经细胞对视觉场景的各种视觉信息特征(大小,形状,颜色,运动速度,空间位置等)的编码逐级分化 (图1)。(2)现在广泛接受的编码理论是视觉神经细胞用放电活动频率表征视觉信息特征。例如初级视觉皮层的一个神经细胞对某个空间位置上垂直方向的线条产生强烈放电(e.g., 50 spikes/second),对其他位置和水平方向的线条放电频率则大幅下降(e.g., 6 spikes/second),甚至不放电。(3)类似功能的神经元分布在相邻的区域,例如早期视觉皮层的功能柱。Hubel 和Wiesel博士在50年代开始对(2)和(3)的开创性的系统研究为他们赢得了1981年诺贝尔奖。(4)Population coding的概念[文献6]:不同区域的视觉皮层中大量神经细胞在同一时刻的反应构成某种特定的放电模式从而表征视觉场景,这种模式可能与表征过去场景的历史模式有某种关系。
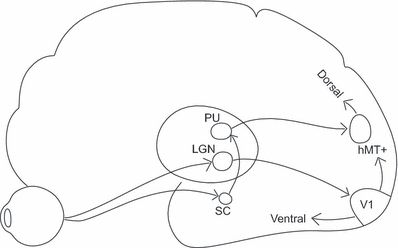
图1,视觉神经通路 (Strand-Brodd K et al. 2011)
关于fMRI信号:(1)虽然具体的量化关系没有定论,fMRI信号的强弱与神经放电的强弱正相关[7]。(2)一个fMRI 像素表征三位空间的一个小区域内(1个立方毫米量级)大量神经元的放电活动,还好如前面提到,这个空间内的神经元的功能比较类似。(3)相对单个神经元的放电活动信号,fMRI信号在时间有延迟(1-10秒)。
2. 神经解码
有了上面的信息,理论上当我们理解了每个神经细胞的放电活动,可以根据足够多的数据完全重现对应的视觉场景。如果我们进一步知道fMRI信号与神经放电活动的数量关系,我们也可以利用fMRI信号精确重建对应的视觉场景。
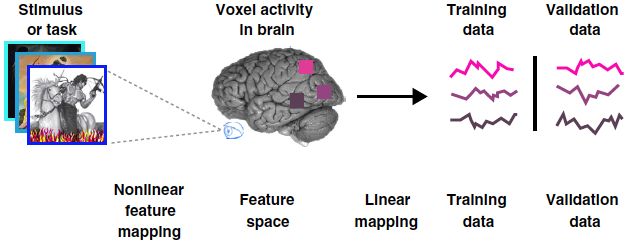
具体实施的时候,也不必理解中间编码的具体过程。根本问题变成求解视觉刺激与脑活动信号(fMRI、脑电、多电极纪录的单个神经元放电等信号)之间的关系。数学上,视觉刺激可以用一个矩阵描述V,脑电信号可以用一个矩阵描述B,中间联系他们的是一个传递函数T,同样用一个矩阵表示。他们之间的关系可以表达为VT=B。如果先通过测量对应一系列的视觉刺激Vi (i=1, ..., N)的脑活动Bi (i=1, ..., N) 可以求出传递函数T,那么在已知B的情况下,可以求出对应的V。文献[3]中论述了这几个矩阵之间的关系,[4]是一个很好的综述,文献[5]是一个具体的应用实例。
补充一下用电极记录的神经放电活动重建视觉场景的研究。第一行和第三行的是视觉刺激,第二行和第四行是相应的重建结果。

神经解码的困难:因为原理和技术的限制,精确地实现神经解码是非常困难。第一个问题是我们对神经编码的理解还十分有限,因而导致我们的测量和建模未必能抓住最核心的参数。第二个困难源于数据采集技术带来的信息局限性。基于不同技术在数据采集精度和对神经系统损伤程度的考虑,现在能获取的数据在时间和空间分辨率都非常有限。第三个挑战是作为编码的逆问题,解码通常是一个病态问题。在有限精度下,两幅场景对应的神经放电模式/fMRI图像可能几乎一致,从而当你看到一幅fMRI的模式,你不能确定反推出到底哪幅图像是本来的刺激图像。在这种情况下,你无法实现视觉场景重建。
3. 几篇关键文献
1)基于LGN神经放电活动的视觉场景重建 (Dr. Dan的工作让我首次了解到神经信号解码的问题):
[1]Dan Y, Atick JJ, Reid RC (1996) Efficient coding of natural scenes in the lateral geniculate nucleus: experimental test of a computational theory. J Neurosci 16:3351–3362.
[2]Dan Y, Alonso J-M, Usrey WM, Reid RC (1998) Coding of visual information by precisely correlated spikes in the LGN. Nat Neurosci 1:501–507.
[3]Stanley GB, Li FF, Dan Y (1999) Reconstruction of Natural Scenes from Ensemble Responses in the Lateral Geniculate Nucleus. The Journal of Neuroscience 19(18): 8036-8042.
2)fMRI信号解码原理及应用
[4]Naselaris et al. (2011) Encoding and decoding in fMRI. NeuroImage 56 (2011) 400-410. (综述)
[5]Shinji Nishimoto, An T. Vu, Thomas Naselaris, Yuval Benjamini, Bin Yu & Jack L. Gallant (2011) Reconstructing Visual Experiences from Brain Activity Evoked by Natural Movies. Current Biology. (应用,按照作者说法可以看看这片文章的价值:This paper presents the first successful approach for reconstructing passively viewed natural movies from brain activity measured by fMRI.)
3)population coding
[6]Alexandre Pouget, Peter Dayan, and Richard S. Zemel (2003) INFERENCE AND COMPUTATION WITH POPULATION CODES. Annual Review of Neuroscience 26: 381-410.
4)fMRI和神经放电活动的关系
[7]Logothetis et al. (2001) Neurophysiological investigation of the basis of the fMRI signal, Nature 412, 150-157.